Appearance
Mesurer la mémoire utilisée
Mesurer la consommation de mémoire de votre application Node.js est important pour optimiser les performances et éviter les fuites de mémoire. Vous pouvez mesurer la mémoire utilisée par Node.js de plusieurs façons.
Commande process.memoryUsage():
Node.js fournit une méthode intégrée, process.memoryUsage(), qui retourne un objet contenant des informations sur l'utilisation de la mémoire.
Voici un exemple simple d'utilisation de process.memoryUsage():
javascript
const memoryUsage = process.memoryUsage();
console.log(memoryUsage);const memoryUsage = process.memoryUsage();
console.log(memoryUsage);L'objet retourné contiendra les informations suivantes:
rss(Resident Set Size): La quantité de mémoire assignée à l'application dans la RAM.heapTotal: La taille totale de la Heap allouée.heapUsed: La quantité de mémoire utilisée dans la Heap.external: La mémoire utilisée par les objets gérés par V8, comme les tampons et les tableaux.
Heap ?
Dans l'informatique, la notion de "Heap" (tas en français) est un concept qui peut sembler un peu abstrait au début, mais je vais essayer de l'expliquer avec une analogie simple.
Analogie:
Imaginez que vous ayez une table sur laquelle vous pouvez placer des boîtes. Chaque boîte peut contenir différentes choses (comme des nombres, du texte, etc.). Cette table est votre mémoire d'ordinateur, et chaque boîte est un espace mémoire où vos variables et données sont stockées.
Maintenant, supposons que vous avez deux zones sur cette table: une zone appelée "Stack" (pile) et une autre zone appelée "Heap" (tas).
Stack:
- La zone "Stack" est très organisée. Chaque boîte placée ici a une taille fixe et est placée et retirée de manière très ordonnée. Les boîtes dans la pile sont très rapides à accéder et à gérer, mais l'espace est limité.
- Exemple: Imaginez que c'est comme une pile d'assiettes dans un restaurant. Vous ne pouvez prendre que l'assiette du dessus, et vous devez replacer les assiettes dans le même ordre.
Heap:
- D'un autre côté, la zone "Heap" est moins organisée. Vous pouvez y placer des boîtes de différentes tailles, et elles peuvent y rester aussi longtemps que vous le souhaitez. L'espace ici est beaucoup plus grand, mais il est plus lent à accéder et à gérer.
- Exemple: C'est comme un entrepôt où vous pouvez stocker différentes choses de différentes tailles pour une période indéfinie.
Heap en informatique:
Dans le contexte de la programmation et de l'informatique, le "Heap" est utilisé pour stocker des données dont la taille peut changer pendant l'exécution du programme, comme des objets et des tableaux qui peuvent grandir ou rétrécir. Par exemple, si vous avez une liste d'éléments et que vous ne savez pas combien d'éléments vous allez ajouter ou retirer à cette liste, vous la mettriez dans le "Heap".
Gestion de la mémoire:
La gestion de la mémoire dans le "Heap" doit être faite avec soin. Contrairement à la "Stack", où la mémoire est gérée automatiquement, vous devez souvent gérer manuellement la mémoire dans le "Heap". Dans des langages comme C et C++, vous devez allouer et libérer la mémoire explicitement. En revanche, dans des langages comme JavaScript (Node.js), Java, et Python, il y a un "Garbage Collector" qui nettoie automatiquement la mémoire non utilisée dans le "Heap".
Utiliser les Outils de Développement de Chrome:
Si vous déboguez votre application avec --inspect, vous pouvez utiliser l'onglet Memory des outils de développement de Chrome pour prendre des instantanés de la mémoire et identifier les fuites de mémoire.
Exemple de Fuite de Mémoire:
Un exemple classique qui pourrait utiliser beaucoup de mémoire RAM en Node.js est celui où vous créez et stockez de nombreux objets en mémoire, par exemple dans un tableau, sans jamais les supprimer. Cela peut être simulé à l'aide d'une boucle qui crée constamment de nouveaux objets et les ajoute à un tableau.
Voici un exemple simple qui générera une consommation de RAM élevée au fil du temps. Notez que cet exemple est à titre éducatif uniquement et ne doit pas être utilisé dans un environnement de production ou de développement réel.
Mauvais exemple
javascript
let bigArray = [];
function createBigObject() {
let obj = {};
for (let i = 0; i < 10000; i++) {
obj[i] = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
}
return obj;
}
function fillMemory() {
while (true) {
bigArray.push(createBigObject());
}
}
fillMemory();let bigArray = [];
function createBigObject() {
let obj = {};
for (let i = 0; i < 10000; i++) {
obj[i] = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
}
return obj;
}
function fillMemory() {
while (true) {
bigArray.push(createBigObject());
}
}
fillMemory();Dans cet exemple:
- Nous avons une fonction
createBigObject()qui crée un objet contenant beaucoup de chaînes de caractères. - La fonction
fillMemory()crée une boucle infinie où de nouveaux objets sont constamment créés et ajoutés àbigArray. - La mémoire continuera à augmenter indéfiniment tant que cette boucle s'exécute, car de plus en plus d'objets sont ajoutés à
bigArrayet aucun n'est supprimé.
Comment Exécuter:
- Copiez ce code dans un fichier, par exemple
memoryLeakExample.js. - Exécutez le fichier avec Node.js dans un terminal:
node memoryLeakExample.js.
Comment Vérifier la Consommation de Mémoire:
Lorsque vous prenez un instantané de la heap (heap snapshot) dans les outils de développement de Chrome, vous verrez plusieurs termes et métriques, dont "Shallow Size", "Retained Size", et "Distance". Ces termes sont utilisés pour analyser l'utilisation de la mémoire de votre application.
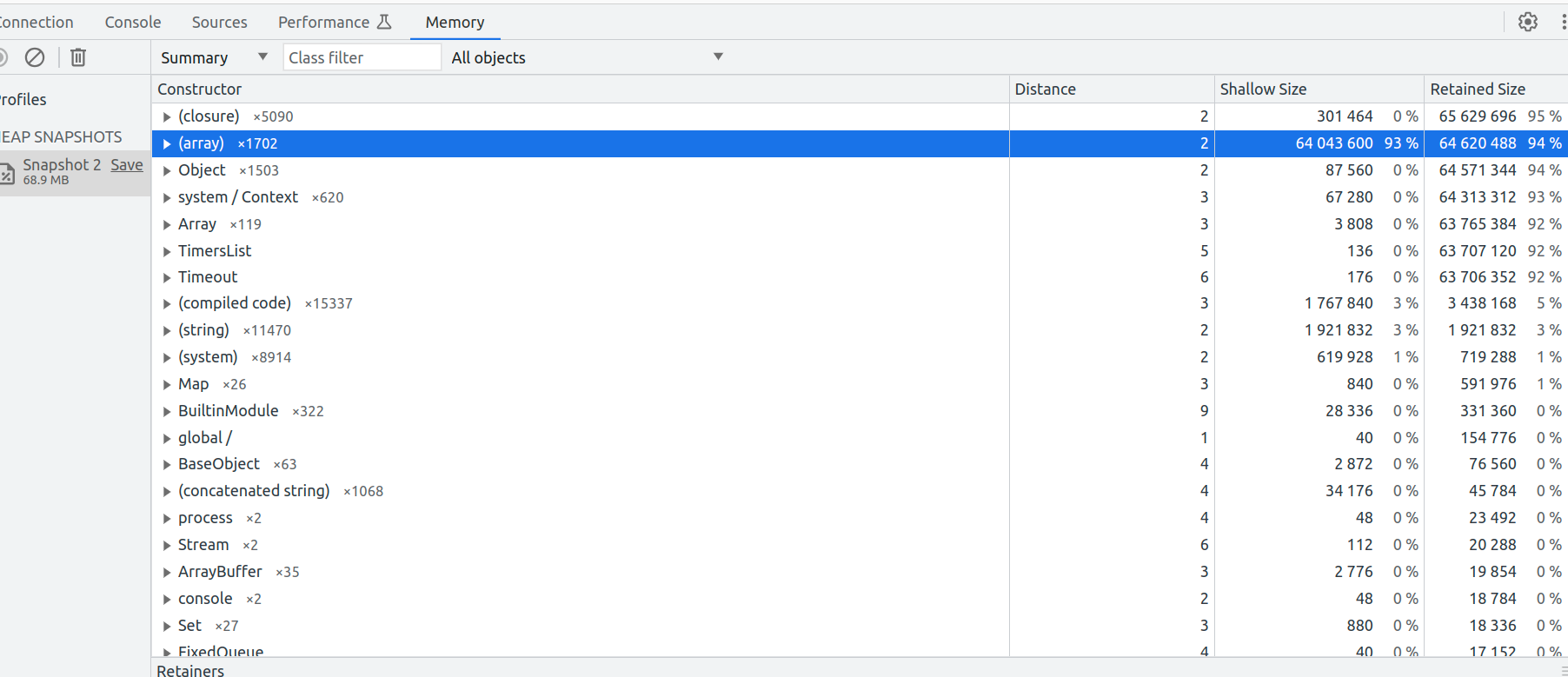
Shallow Size & Retained Size
La taille shallow d'un objet représente la quantité de mémoire utilisée par l'objet lui-même, sans compter les objets référencés. C'est, en d'autres termes, la quantité de mémoire que vous récupéreriez immédiatement si vous supprimiez l'objet (et uniquement cet objet).
La taille retained d'un objet est la quantité totale de mémoire que vous récupéreriez si vous supprimiez cet objet et tous les autres objets qui sont inaccessibles sans lui. En d'autres termes, c'est la somme de la taille shallow de l'objet et de toutes les tailles shallow des objets qui seraient libérés si cet objet était supprimé.
Bien comprendre
Le concept de "Shallow Size" (taille superficielle) peut être comparé à la quantité d'espace qu'un conteneur occupe sans considérer l'espace occupé par son contenu. C'est la taille de l'objet lui-même, sans prendre en compte les objets auxquels il fait référence.
Exemple de tous les jours:
Imaginons que vous ayez une boîte (un conteneur) dans votre maison. Cette boîte peut contenir plusieurs objets, comme des livres, des jouets, etc.
Shallow Size (Taille Superficielle): C'est la taille de la boîte elle-même, sans considérer les objets qu'elle contient. Si la boîte mesure 30x30x30 cm, la taille superficielle de la boîte serait la quantité d'espace qu'elle occupe, soit 27 000 cm³, indépendamment de ce qu'elle contient.
Retained Size (Taille Retenue): Cela inclurait la taille de la boîte plus la taille de tous les objets à l'intérieur de celle-ci et, potentiellement, la taille de tout ce qui est contenu à l'intérieur de ces objets, si ces objets ne peuvent être accessibles qu'à partir de la boîte initiale.
Application en Programmation:
En programmation, et spécifiquement dans le contexte de Node.js ou JavaScript:
- Shallow Size (Taille Superficielle): Pour un objet, la taille superficielle serait la quantité de mémoire utilisée pour stocker l'objet lui-même, sans prendre en compte les objets référencés par celui-ci. Par exemple, si vous avez un objet avec trois propriétés numériques, la taille superficielle de cet objet serait la quantité de mémoire nécessaire pour stocker ces trois nombres et les métadonnées de l'objet, indépendamment des autres objets qu'il pourrait référencer.
En comprenant la différence entre la "Shallow Size" et la "Retained Size", vous pouvez avoir une meilleure idée de la façon dont la mémoire est utilisée dans vos applications et comment les optimisations peuvent affecter la consommation globale de mémoire.
Distance:
La distance dans un instantané de la heap représente la distance minimale de l'objet par rapport à la racine de la heap, en nombre d'arêtes. Une distance plus courte signifie que l'objet est plus proche de la racine de la heap, et une distance plus longue signifie qu'il est plus éloigné.
La notion de "distance" dans le contexte de l'analyse de la mémoire en informatique se réfère généralement à la distance entre un objet spécifique dans le tas de mémoire (heap) et la racine de l'arbre d'objets.
Bien Comprendre la distance
Imaginons un arbre généalogique. L'ancêtre le plus ancien est à la racine de l'arbre. La "distance" d'un membre de la famille à cet ancêtre serait le nombre de générations entre eux. Donc, vos parents auraient une distance de 1 par rapport à vous, vos grands-parents une distance de 2, et ainsi de suite.
Application en Informatique: Dans l'analyse de mémoire, la "racine" serait un objet global ou un autre objet qui est directement accessible (par exemple, une variable globale dans un programme). Les autres objets sont connectés à la racine par des références, formant une structure d'arbre.
- Distance 0 : Les objets directement accessibles, comme les variables globales, auraient une distance de 0.
- Distance 1 : Les objets référencés par des objets de distance 0 auraient une distance de 1.
- Distance 2 : Les objets référencés par des objets de distance 1 auraient une distance de 2, et ainsi de suite.
Pourquoi est-ce Important ? Cette notion de distance est importante pour comprendre les fuites de mémoire et optimiser l'utilisation de la mémoire dans les applications, car les objets avec de longues chaînes de références peuvent être plus difficiles à déréférencer et à nettoyer par le garbage collector, pouvant ainsi causer une utilisation élevée de la mémoire. En général, une distance plus courte signifie que l'objet est plus directement accessible dans le code, alors qu'une distance plus longue peut indiquer un objet qui est profondément imbriqué ou retenu en mémoire par une chaîne complexe de références.
Exemple de Code (longue distance)
DANGER
javascript
let root = { name: "root" }; // objet racine
let current = root; // objet courant, initialement défini comme l'objet racine
// Création d'une chaîne d'objets imbriqués
for (let i = 0; i < 10; i++) {
current.child = { name: `child${i}` }; // crée un nouvel objet et l'assigne à la propriété "child" de l'objet courant
current = current.child; // déplace la référence de l'objet courant vers le nouvel objet enfant
}
console.log(root);let root = { name: "root" }; // objet racine
let current = root; // objet courant, initialement défini comme l'objet racine
// Création d'une chaîne d'objets imbriqués
for (let i = 0; i < 10; i++) {
current.child = { name: `child${i}` }; // crée un nouvel objet et l'assigne à la propriété "child" de l'objet courant
current = current.child; // déplace la référence de l'objet courant vers le nouvel objet enfant
}
console.log(root);Dans cet exemple:
- Nous avons un objet
rootinitial. - Une boucle crée une série d'objets imbriqués (chaque objet est un "enfant" du précédent), créant une chaîne d'objets.
Analyse de la Distance:
- L'objet
rootaurait une distance de0, car il est directement accessible. root.child(i.e.,child0) aurait une distance de1deroot.root.child.child(i.e.,child1) aurait une distance de2deroot, et ainsi de suite.- Le dernier enfant créé aurait une distance de
10de l'objetroot, car il est imbriqué à travers 10 niveaux d'objets.
Cet exemple est simplifié, mais il illustre comment les objets peuvent être imbriqués ou référencés à travers plusieurs niveaux, créant une "longue distance" entre la racine et l'objet final dans la chaîne d'objets. Dans des applications réelles, cela peut se produire de manière plus complexe à travers des structures de données imbriquées, des closures, des callbacks, et d'autres constructions de code.
Utiliser Efficacement le Heap Snapshot pour les Fuites de Mémoire:
Prendre plusieurs instantanés:
- Prenez un instantané de la heap au début.
- Exécutez ensuite des parties de votre application susceptibles de causer des fuites de mémoire.
- Prenez d'autres instantanés pour comparer les résultats.
Comparer les Instantanés:
- Comparez les instantanés de la heap pour voir quels objets restent en mémoire.
- Les objets qui ne sont pas libérés peuvent être à l'origine de fuites de mémoire.
Identifier les Objets Conservés:
- Recherchez les objets qui ont une grande taille retained, car cela peut indiquer qu'ils conservent d'autres objets en mémoire.
- Examinez ces objets pour voir pourquoi ils ne sont pas libérés.
Recherchez les Détenteurs de Mémoire:
- Les détenteurs de mémoire sont des objets qui retiennent d'autres objets en mémoire.
- Examinez les relations entre les objets et identifiez ceux qui retiennent inutilement d'autres objets.
Inspecter la Distance:
- Considérez la distance pour comprendre si un objet est retenu à cause d'une référence profondément imbriquée.
- Les objets avec une distance plus courte sont généralement créés et référencés directement par le code de l'application, tandis que ceux avec une distance plus longue peuvent être créés indirectement.
Références et Chemins:
- Utilisez l'onglet "References" pour voir quelles sont les références qui retiennent l'objet.
- Utilisez l'onglet "Paths" pour voir le chemin de références qui retient l'objet.
Retained Size
La taille "retained" (retenue) d'un objet en mémoire est un concept que l'on utilise lors de l'analyse de la mémoire dans les applications, notamment pour identifier les fuites de mémoire. Elle est généralement utilisée dans le contexte des outils de profiling de mémoire comme les DevTools de Chrome pour les applications JavaScript, y compris Node.js.
Définition de la Taille Retained:
La "Retained Size" d'un objet représente la quantité totale de mémoire qui serait libérée si cet objet était supprimé de la mémoire. Plus précisément, elle comprend la mémoire utilisée par l'objet lui-même (sa "Shallow Size") ainsi que la mémoire utilisée par d'autres objets qui sont référencés directement ou indirectement par cet objet et qui ne sont accessibles (et donc retenus en mémoire) que par cet objet.
Exemple:
Imaginons que vous ayez trois objets en mémoire: A, B, et C.
Aa une référence àB.Ba une référence àC.
Si A est le seul objet qui a une référence à B, et B est le seul objet qui a une référence à C, alors la "Retained Size" de A inclura la "Shallow Size" de A, B, et C, car si vous supprimez A, alors B et C seront également éligibles pour la collecte des ordures (garbage collection), étant donné qu'il n'y a plus de références à B et C.
Code Exemple:
Voici un exemple concret d’un scénario où vous pourriez rencontrer une situation de grande taille "retained" dans un serveur web Node.js. Supposons que vous ayez un serveur qui conserve tous les objets de requête dans un tableau pour une raison quelconque (cet exemple est simplifié et à des fins éducatives, et il n'est généralement pas conseillé de conserver toutes les requêtes).
javascript
import express from 'express';
const app = express();
const port = 3000;
let requests = []; // Pour stocker tous les objets de requête
app.get('/', (req, res) => {
requests.push(req); // Ajouter chaque objet de requête au tableau
res.send('Hello World!');
});
app.listen(port, () => {
console.log(`Server is running at http://localhost:${port}`);
});import express from 'express';
const app = express();
const port = 3000;
let requests = []; // Pour stocker tous les objets de requête
app.get('/', (req, res) => {
requests.push(req); // Ajouter chaque objet de requête au tableau
res.send('Hello World!');
});
app.listen(port, () => {
console.log(`Server is running at http://localhost:${port}`);
});Scénario:
Dans cet exemple, à chaque requête reçue sur l'endpoint '/', l'objet req (qui représente la requête HTTP entrante) est ajouté au tableau requests. Si cet objet req a des références à d'autres objets, ces objets sont également retenus en mémoire tant que l'objet req est dans le tableau requests.
Retained Size:
Dans ce cas, la taille "retained" de chaque objet req dans le tableau serait la somme de la taille "shallow" de l'objet req lui-même et des tailles "shallow" de tous les objets accessibles depuis req.
Analyse avec Chrome DevTools:
Pour analyser la taille "retained" et identifier les fuites de mémoire, vous pouvez prendre un Heap Snapshot à l'aide de Chrome DevTools. Vous aurez besoin d'exécuter votre serveur Node.js avec l'option --inspect, puis connecter Chrome DevTools à l'instance en cours d'exécution de Node.js.
Voici comment faire:
Exécuter le Serveur avec l'Option
--inspect:shnode --inspect server.jsnode --inspect server.jsOuvrez Chrome et Naviguez vers:
chrome://inspectchrome://inspectConnectez-vous à l'Instance de Node.js: Sous "Remote Target", vous devriez voir votre instance de Node.js en cours d'exécution. Cliquez sur "inspect".
Prenez un Heap Snapshot:
- Allez à l'onglet "Memory".
- Cliquez sur "Take snapshot".
Analysez la Taille Retained:
- Examinez les objets dans le snapshot et vérifiez leur taille "retained".
En faisant cela, vous pouvez identifier les objets qui occupent le plus de mémoire et optimiser votre code en conséquence. Dans le cas de cet exemple, vous constaterez que le tableau requests et ses objets de requête ont une grande taille "retained", ce qui indique qu'ils retiennent beaucoup de mémoire.